Discrétisation de données
Exercices sur la création de classes de données avec pandas.
Objectifs
- Explorer et manipuler des données
- Créer des classes de données
Exercices
Amplitude fixe
NoteConsignes
- Créez une colonne dans le tableau
piben divisant la colonnePIB_haben 3 catégories d’amplitude égale : faible < moyen < élevé. Dans quelle catégorie se trouve Neuchâtel ? - Combien de valeurs chacune des catégories contient-elle ?
- Avancé: Que se passe-t-il si on créé 4 catégories d’amplitude égale ?
Note
Utilisez la fonction pd.cut() pour créer des catégories d’amplitude fixe.
Les paramètres importants sont :
bins: le nombre de catégories ou les seuils des catégorieslabels: les étiquettes des catégories (optionnel)
Astuce
# Amplitude fixe avec 3 catégories
pib['ampl_3'] = pd.cut(pib['PIB_hab'], bins=3, labels=['faible', 'moyen', 'élevé'])
pib[pib['Canton'] == "Neuchâtel"][['Canton', 'ampl_3']]
pib['ampl_3'].value_counts().sort_index()
# Amplitude fixe avec 4 catégories
pib['ampl_4'] = pd.cut(pib['PIB_hab'], bins=4)
pib['ampl_4'].value_counts().sort_index()Effectifs fixes
NoteConsignes
- Créez une colonne dans le tableau
piben divisant la colonnePIB_haben 3 catégories d’effectifs fixes : faible < moyen < élevé. Dans quelle catégorie se trouve Neuchâtel à présent ? - Combien de valeurs chacune des catégories contiennent-elles ?
Note
Utilisez la fonction pd.qcut() pour créer des catégories d’effectifs fixes.
Les paramètres importants sont :
q: le nombre de catégorieslabels: les étiquettes des catégories (optionnel)
Astuce
pib['q3'] = pd.qcut(pib['PIB_hab'], q=3, labels=['faible', 'moyen', 'élevé'])
pib[pib['Canton'] == "Neuchâtel"][['Canton', 'q3']]
pib['q3'].value_counts().sort_index()Avancé: Seuils observés
NoteConsignes
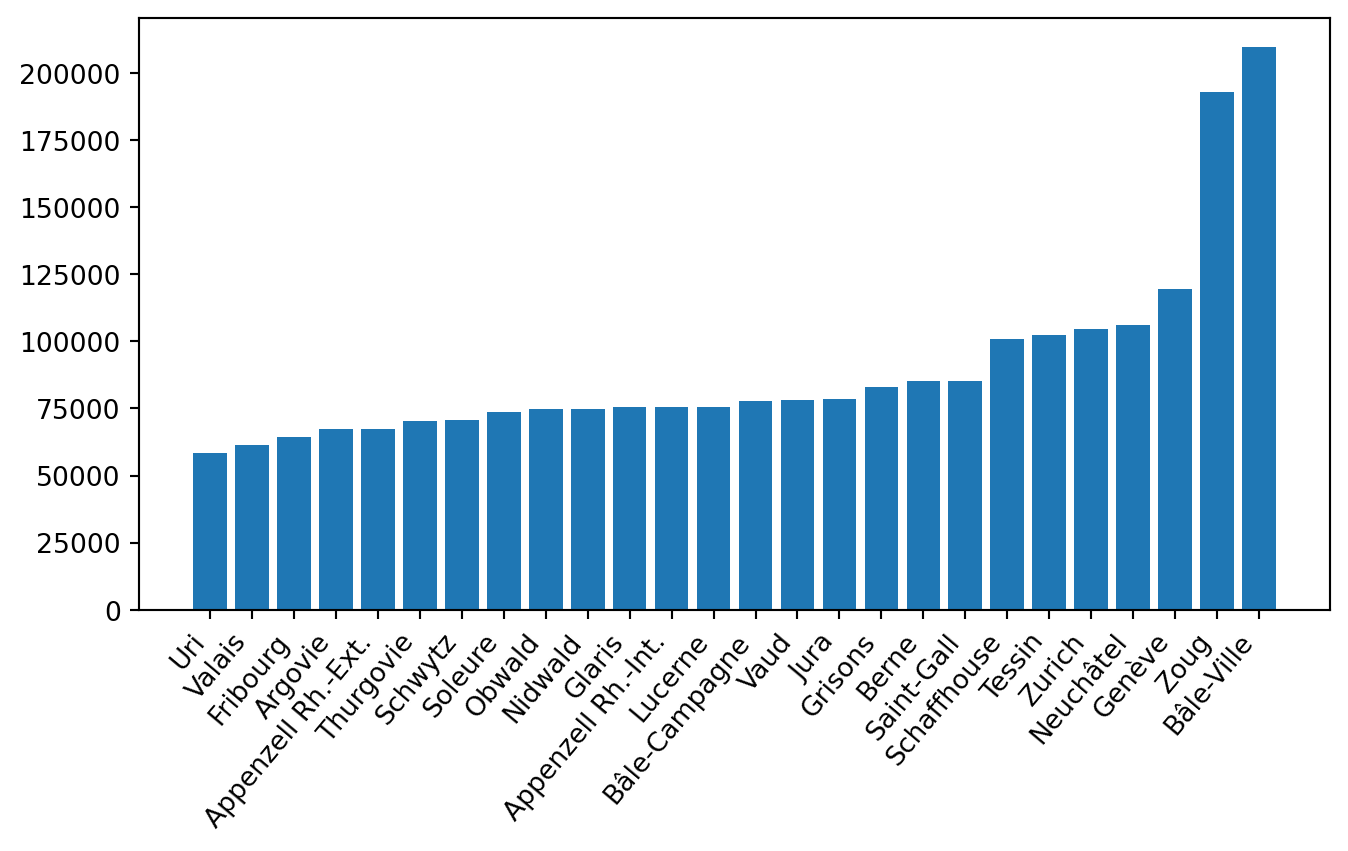
- Considérez le graphique du PIB par habitants.
- Créez une colonne dans le tableau
piben divisant la colonnePIB_haben 3 catégories manuelles. Quelle répartition vous semblent la plus pertinente ?
NoteGraphique
Note
Utilisez la fonction pd.cut() pour créer des catégories avec des seuils personnalisés.
Les paramètres importants sont :
bins: les seuils des catégories, une liste de valeurs, par exemple[0, 50000, 100000]labels: les étiquettes des catégories (optionnel)
Astuce
pib['man_3'] = pd.cut(pib['PIB_hab'], bins=[0,90000,150000,250000])
pib['man_3'].value_counts().sort_index()